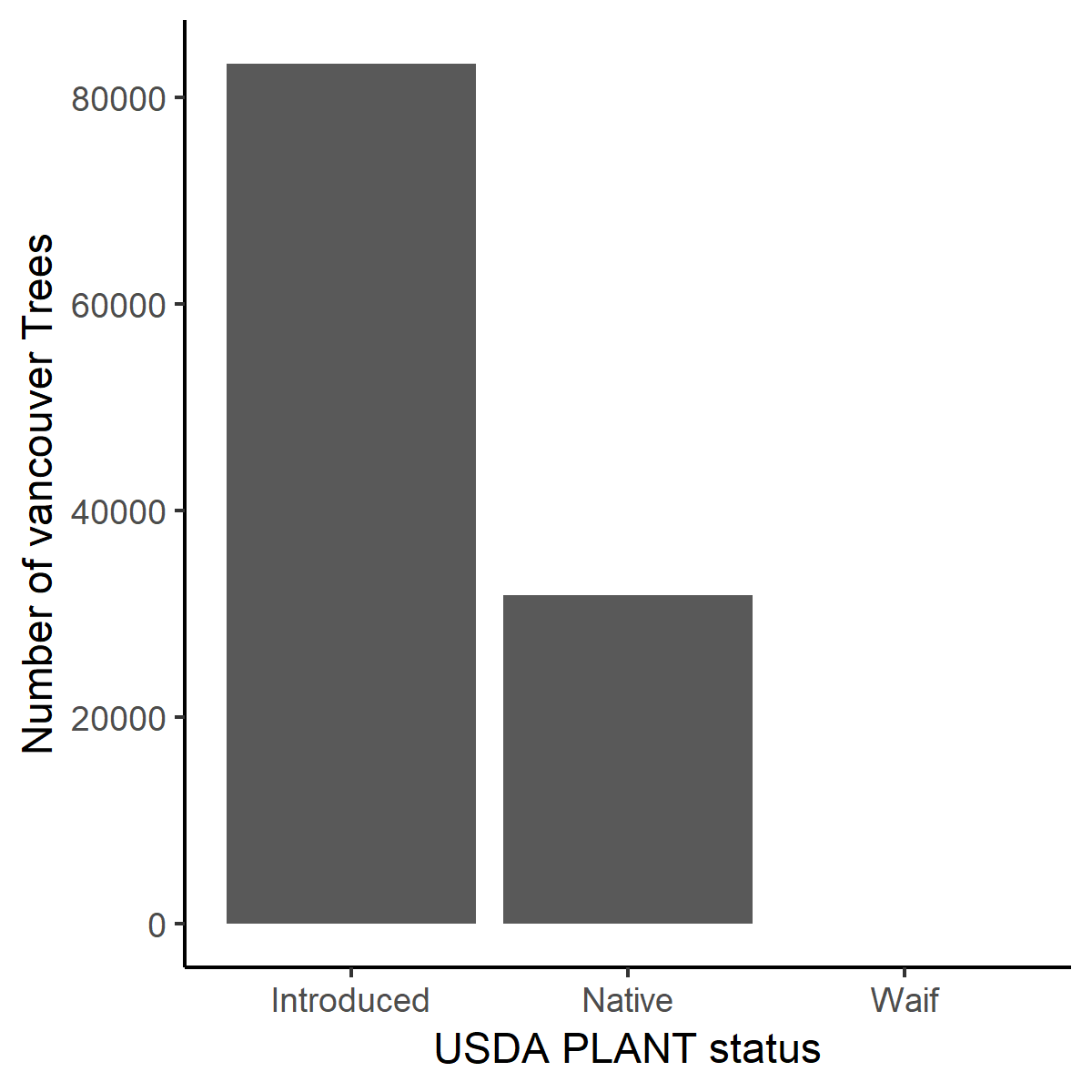
Motivation: I converted a KML shape file into a data frame in my previous post on cherry trees in Vancouver but I figured I should learn to actually work with shape files. I thought an easy figure to make was to show which parts of Vancouver had introduced trees and native trees but it turned out harder than I thought. Fortunately, what I learned about using geospatial packages came in helpful for making maps such as the one for Lythrum salicaria spread..
This first part is on getting native/introduced status on the tree species in Vancouver. The second part will be on visualization of tree location in Vancouver.
The main technique in this post is automated web scraping of webpages.
library(rgdal)## Warning: package 'rgdal' was built under R version 3.6.2## Loading required package: sp## Warning: package 'sp' was built under R version 3.6.2## rgdal: version: 1.4-8, (SVN revision 845)
## Geospatial Data Abstraction Library extensions to R successfully loaded
## Loaded GDAL runtime: GDAL 2.2.3, released 2017/11/20
## Path to GDAL shared files: C:/Users/YIHANWU/Documents/R/win-library/3.6/rgdal/gdal
## GDAL binary built with GEOS: TRUE
## Loaded PROJ.4 runtime: Rel. 4.9.3, 15 August 2016, [PJ_VERSION: 493]
## Path to PROJ.4 shared files: C:/Users/YIHANWU/Documents/R/win-library/3.6/rgdal/proj
## Linking to sp version: 1.3-2library(sp)
library(raster)## Warning: package 'raster' was built under R version 3.6.2library(dplyr)## Warning: package 'dplyr' was built under R version 3.6.2##
## Attaching package: 'dplyr'## The following objects are masked from 'package:raster':
##
## intersect, select, union## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionThe City of Vancouver offers its trees and assorted information as a shapefile. The KML file used here is the same one as before. Additionally, I downloaded the USDA list of species and acronyms here.
# read in trees df
trees_df <- read.csv("StreetTrees_CityWide.csv")
# read in polygons
# locmap<-readOGR("cov_localareas.kml", "local_areas_region", stringsAsFactors = F)
# read in USDA PLANTS checklist
usda_symbol <- read.delim("USDA_PLANTS_checklist.txt", sep=",", stringsAsFactors = F)trees_df$SCIENTIFIC_NAME <- paste(trees_df$GENUS_NAME, trees_df$SPECIES_NAME)The best source for the native/introduced status of plants in North America, as far as I can find, is the USDA PLANTS Database. To get the “native status” for each species, I had to find the species page on the PLANTS website, and then extract the status. All of this could be automated through packages by Hadley Wickham and some poking around the html source for the PLANTS species webpages.
# get tree native/invasive status
library(httr)
library(rvest)## Warning: package 'rvest' was built under R version 3.6.2## Loading required package: xml2library(purrr)##
## Attaching package: 'purrr'## The following object is masked from 'package:rvest':
##
## plucklibrary(tidyr)## Warning: package 'tidyr' was built under R version 3.6.2##
## Attaching package: 'tidyr'## The following object is masked from 'package:raster':
##
## extractinfo_getter<-function(x, usda_symbol){
symbol_results<-usda_symbol[grep(tolower(x), tolower(usda_symbol$Scientific.Name.with.Author), fixed=T),]
if(nrow(symbol_results) > 0) {
species_symbol<-symbol_results$Symbol[1]
species_url<-paste0("https://plants.usda.gov/core/profile?symbol=", species_symbol)
usda_page<-read_html(species_url)
check <- usda_page %>% html_node("#tabGeneral") %>% html_nodes(xpath=".//table[@class ='bordered']") %>% html_table()
return(data.frame(t(c(x,gsub("\t", "", check[[1]][1:6,2])))))
} else {
return(data.frame(t(c(x, rep("NA", 6)))))
}
}This info_getter function will find the USDA abbreviation for each species and then access the webpage. The “native status” is located within a table which could be extracted with help from rvest functions. XPath is a wonderful thing which I still do not know how to use properly but is very helpful.
In this data set, some hybrid trees have the second genus in the “species” column followed by an “x”. So the paste will create “genus genus x” rather than “genus x genus” which is the more common format. So species_correction is a function to check if there is an x at the end of the “species” value for each row, and produce “genus x genus” rather than “genus genus x”.
trees_df$GENUS_NAME <- as.character(trees_df$GENUS_NAME)
trees_df$SPECIES_NAME <- as.character(trees_df$SPECIES_NAME)
species_correction <- function(genus, species){
if(species == "SPECIES"){
return(genus)
} else if (length(grep("\\sX$", species)) > 0){
return(paste(genus," x ", unlist(strsplit(species, " "))[[1]]))
} else {
return(paste(genus, species))
}
}
# example
species_correction("GENUS1", "GENUS2 X")## [1] "GENUS1 x GENUS2"trees_df$SCIENTIFIC_NAME <- map2_chr(trees_df$GENUS_NAME, trees_df$SPECIES_NAME, species_correction)Rather than go through every row in the data set, 145066, it is time-efficient to use get a list of unique species.
unique_species <- toupper(unique(trees_df$SCIENTIFIC_NAME))There are 357 pages to look up which is much better.
city_plant_info <- map_dfr(unique_species, .f = info_getter, usda_symbol=usda_symbol)Running this the first time does take some time so the results should be saved.
write.csv(city_plant_info, "usda_plant_info.csv", row.names=F)And the file could be read back in after a break for further analysis. We can filter out the species without any status.
city_plant_info <- read.csv("usda_plant_info.csv", stringsAsFactors = F)
head(city_plant_info)
city_plant_info <- city_plant_info[!is.na(city_plant_info$X7), ]USDA plants provides plant status for both the lower US, Canada and other US territories, all separated by empty spaces and line endings. To actually use this data for just Canada only, the statuses have to be formatted which can be accomplished using regular expressions.
matches <- regexpr("CAN\\s+[?a-zA-Z]+",city_plant_info$X7)
out <- rep(NA,length(city_plant_info$X7))
out[matches!=-1] <- regmatches(city_plant_info$X7, matches)
city_plant_info$CAN <- outThe above four lines first finds all rows where there is a Canadian status, and then extract the status using the regmatches function in R.
We can do this for the US statuses and then clean up the status by removing the “CAN” and “US”.
# us status
matches <- regexpr("L48\\s+[?a-zA-Z]+",city_plant_info$X7)
out <- rep(NA,length(city_plant_info$X7))
out[matches!=-1] <- regmatches(city_plant_info$X7, matches)
city_plant_info$US <- out
# extract status
matches <- regexpr("\\w$",city_plant_info$CAN)
out <- rep(NA,length(city_plant_info$CAN))
out[!is.na(matches)] <- regmatches(city_plant_info$CAN, matches)
city_plant_info$CAN <- out
matches <- regexpr("\\w$",city_plant_info$US)
out <- rep(NA,length(city_plant_info$US))
out[!is.na(matches)] <- regmatches(city_plant_info$US, matches)
city_plant_info$US <- outAlso, the data frame names are not very informative.
names(city_plant_info) <- c("SCIENTIFIC_NAME", "Symbol", "Group", "Family", "Duration", "Growth_Habit", "Native_Status", "CAN", "US")There are some species with no Canadian status but US status. So we can make a summary status that uses US information when CAN information is not available.
determination <- function(can, us){
if (is.na(can)){
return(us)
} else if (is.na(us)){
return(can)
} else if(can=="I" & us == "I"){
return("I")
} else if (can == "N" & us == "N"){
return("N")
} else if (can == "I" & us == "N"){
return("I")
} else if (can == "N" & us == "I"){
return("N")
}
}
city_plant_info$status <- map2_chr(city_plant_info$CAN, city_plant_info$US, determination)
write.csv(city_plant_info, "vancouver_info.csv", row.names=F)Now we know the native/introduced status as best as we can from the USDA database.
trees_df <- left_join(trees_df, city_plant_info)
library(ggplot2)
p <- ggplot(trees_df[!is.na(trees_df$status),]) + geom_bar(aes(x=status)) + theme_classic() + labs(x="USDA PLANT status", y = "Number of vancouver Trees") + scale_x_discrete(labels = c("Introduced", "Native", "Waif"))
psessionInfo()## R version 3.6.1 (2019-07-05)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 18363)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=English_Canada.1252 LC_CTYPE=English_Canada.1252
## [3] LC_MONETARY=English_Canada.1252 LC_NUMERIC=C
## [5] LC_TIME=English_Canada.1252
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] tidyr_1.0.2 purrr_0.3.3 rvest_0.3.5 xml2_1.2.2 httr_1.4.1
## [6] dplyr_0.8.4 raster_3.0-12 rgdal_1.4-8 sp_1.3-2
##
## loaded via a namespace (and not attached):
## [1] Rcpp_1.0.3 knitr_1.28 magrittr_1.5 tidyselect_1.0.0
## [5] lattice_0.20-38 R6_2.4.1 rlang_0.4.4 stringr_1.4.0
## [9] tools_3.6.1 grid_3.6.1 xfun_0.12 htmltools_0.4.0
## [13] yaml_2.2.1 digest_0.6.23 assertthat_0.2.1 lifecycle_0.1.0
## [17] tibble_2.1.3 crayon_1.3.4 bookdown_0.17 vctrs_0.2.2
## [21] codetools_0.2-16 glue_1.3.1 evaluate_0.14 rmarkdown_2.1
## [25] blogdown_0.17 stringi_1.4.3 pillar_1.4.3 compiler_3.6.1
## [29] pkgconfig_2.0.3